
연구실에서 갑자기 논문들에 대한
1. selenium 이란?
셀레니움의 원래 용도는 웹 테스트 자동화 프레임워크이다.
BeautifulSoup 같은 다른 웹 수집기도 있지만 이러한 수집기들은 Javascript로 실행하는 비동기적인 컨텐츠(뒤 늦게 불려와지는 컨텐츠)들은 수집하기 어려운 단점이 있다. 셀레니움을 크롤러로 사용했을 때 웹드라이버를 통하여 실제 사람이 사용하는 것과 비슷하게 작동하기 때문에
아직 많이 사용해 보지 않아서 정확한 단점은 알 수 없지만 처음 사용해 봤을 때 느낀점은 수집이 느리다는 단점이 있었다. 하지만 보이는 곳 어디든 수집이 가능하다는 장점이 있다.
2. selenium 설치
셀레니움은 pip를 이용하여 간단하게 설치할 수 있다. 그리고 페이지를 랜더링 한 후 html을 파싱해올 때 BeutifulSoup4를 사용하므로 만약에 설치되어 있지 않다면 같이 설치해준다.
$ pip install selenium
$ pip install bs43. 크롬 브라우저 설치 및 크롬 웹드라이버 다운로드
우선 셀레니움은 webdriver를 이용하여 작동하는데 기본적으로 많이 사용하는
아래의 주소에서 크롬 드라이버를 다운로드 받을 수 있다(GUI 환경)
- 크롬 드라이버 다운로드 : https://sites.google.com/a/chromium.org/chromedriver/downloads

위의 홈페이지 url로 접속해보면 이렇게 크롬 웹 드라이버를 받을 수 있는 화면이 나온다. 오른쪽 중간쯤에 Latest Release의 크롬 드라이버링크를 클릭한다.
들어가보면 운영체제 별로 웹 드라이버를 다운로드 받을 수 있게 되어 있다.
1) Windows 10 / MAC OS(GUI 가능)
반드시 운영체제에 맞는 드라이버를 다운로드 받아야 한다. 웹 드라이버를 다운로드 받게되면 압축파일이 받아지게 되는데 압축을 풀고난 크롬드라이버를 파이썬 코드와 같은 경로에 두거나 경로를 기억해둔다. 나는 압축을 풀고 웹 드라이버 파일을 파이썬 코드 파일과 동일한 경로에 두었다.
2) Ubuntu 16.04(GUI 불가능) + Docker 컨테이너 환경
서버에서는
도커 컨테이너 내에서는 sudo 명령어를 사용하지 않는다. 먼저
# 크롬 apt-get에 추가
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub
$ apt-key add -
# apt-get 업데이트
$ apt-get update
# 크롬 브라우저 설치
$ apt-get install google-chrome-stable그 다음
# Downloads 폴더에 드라이버 다운로드
$ wget -N http://chromedriver.storage.googleapis.com/2.10/chromedriver_linux64.zip -P ~/Downloads
# 압축 풀기
$ apt-get install unzip
$ unzip ~/Downloads/chromedriver_linux64.zip
# 프로젝트 폴더 안에 크롬 드라이버 넣어주기
$ mv -f ~/Downloads/chromedriver 프로젝트 경로입력4. selenium 코드 테스트
우분투 서버 환경에서는 GUI를 지원하지 않기 때문에 세 환경 모두
from selenium import webdriver
options = webdriver.ChromeOptions()
# headless 옵션 설정
options.add_argument('headless')
options.add_argument("no-sandbox")
# 브라우저 윈도우 사이즈
options.add_argument('window-size=1920x1080')
# 사람처럼 보이게 하는 옵션들
options.add_argument("disable-gpu") # 가속 사용 x
options.add_argument("lang=ko_KR") # 가짜 플러그인 탑재
options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36') # user-agent 이름 설정
# 드라이버 위치 경로 입력
driver = webdriver.Chrome('./chromedriver.exe', chrome_options=options)
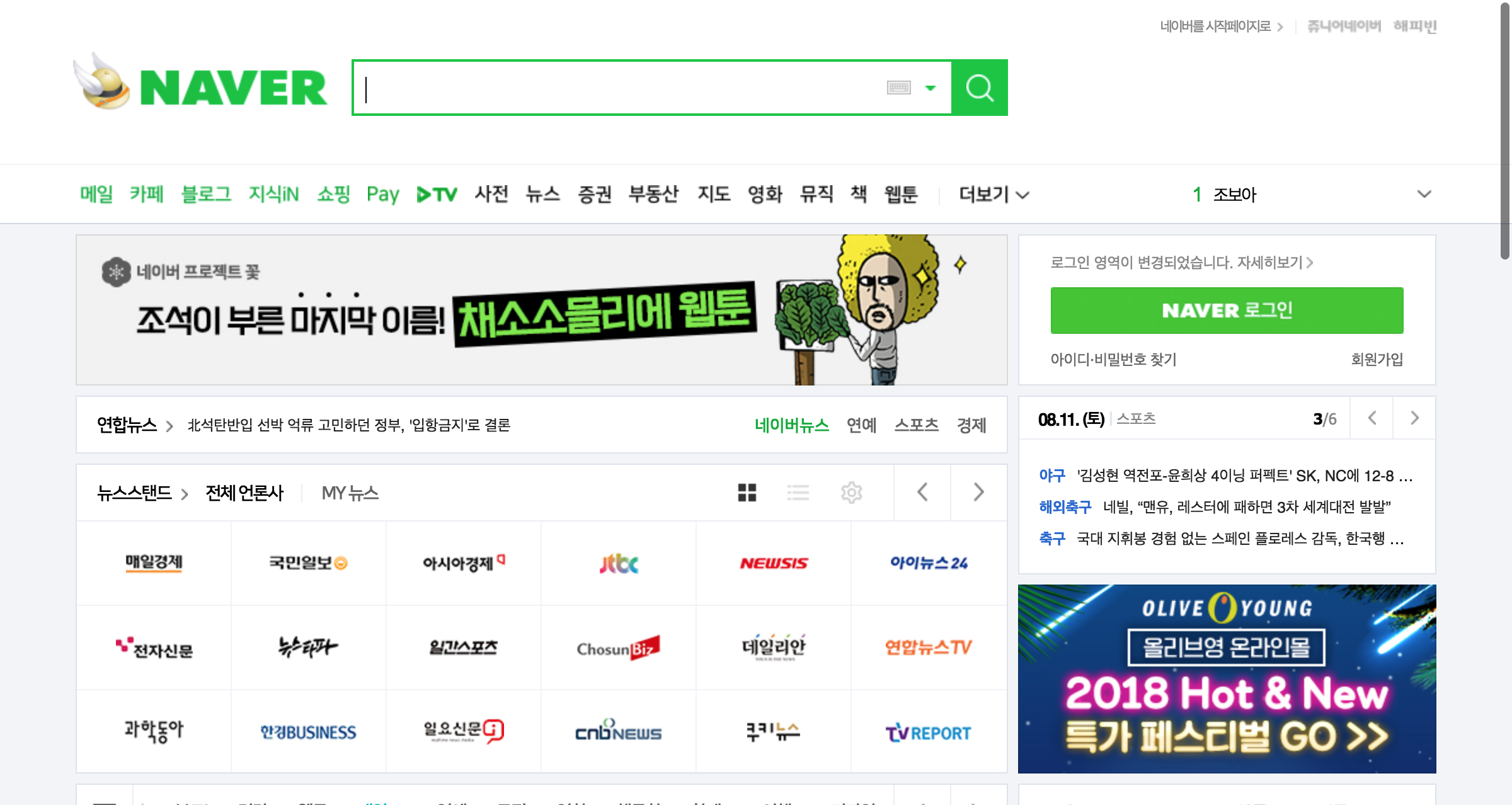
driver.get('https://naver.com')
driver.implicitly_wait(3)
driver.get_screenshot_as_file('capture_naver.png') # 화면캡처
driver.quit() # driver 종료
캡쳐화면을 확인해보면 아래와 같다.
reference
- https://beomi.github.io/2017/02/27/HowToMakeWebCrawler-With-Selenium/
- http://selenium-python.readthedocs.io/
- http://ocsusu.tistory.com/61